コンパイル
前回、私たちは最初のプログラムをC言語で書き、「hello, world」を画面に表示することを学びました。 まずmake helloでコンパイルし、ソースコードをマシンコードに変換してから、./helloでコンパイルしたプログラムを実行しました。 make は実際のところ、オプション付きでコンパイラであるclangを呼び出すプログラムにすぎません。ソースコードファイルhello.cをコンパイルするには、clang hello.cコマンドを実行します。何も起きていないようですが。これはエラーがなかったということです。lsを実行すると、a.outファイルがディレクトリに表示されます。ファイル名はデフォルトのままなので、より具体的に指定するコマンドclang -o hello hello.cを実行できます。別のコマンドライン引数 、またはコマンドライン上のプログラムへの入力を、プログラム名の後に追加しました。clangはプログラムの名前で、-o,、hello、およびhello.cは追加の引数です。clang には、出力ファイル名 としてhello を使用し、ソースコードとしてhello.cを使用するように指示しています。これで、出力としてhelloが作成されたことがわかります。 get_string関数の利用のためCS50のライブラリを #include <cs50.h> で使用する場合は、フラグ clang -o hello hello.c -lcs50も追加する必要があります。 #include <cs50.h>
#include <stdio.h>
int main(void)
{
string name = get_string("What's your name? ");
printf("hello, %s\n", name);
}
-lフラグはCS50 IDEに既にインストールされているcs50ファイルにリンクし、プログラムが参照して使用できる (さまざまな関数の中から) get_stringのマシンコードを含みます。CS50 IDEではすでにこれらの引数が生成されるようmakeが設定されています。 ソースコードのマシンコードへのコンパイルは、実際にはより小さなステップから構成されています。 前処理 には通常、#include のように # で始まる行が含まれます。例えば、#include <cs50.h> は clang にそのヘッダファイルを探すように指示します。なぜなら、プログラムに含めたい内容が含まれているからです。その後、clang はこれらのヘッダファイルの内容をプログラムに置き換えます。例えば、以下のようなものです。 #include <cs50.h>
#include <stdio.h>
int main(void)
{
string name = get_string("What's your name? ");
printf("hello, %s\n", name);
}
...
string get_string(string prompt);
int printf(string format, ...);
...
int main(void)
{
string name = get_string("Name: ");
printf("hello, %s\n", name);
}
これには、インクルードしたライブラリのすべての関数のプロトタイプが含まれているため、コードで使用できます。 コンパイル では、ソースコードであるC言語を取得し、アセンブリコード と呼ばれる別のタイプのソースコードに変換します。...
main: # @main
.cfi_startproc
# BB#0:
pushq %rbp
.Ltmp0:
.cfi_def_cfa_offset 16
.Ltmp1:
.cfi_offset %rbp, -16
movq %rsp, %rbp
.Ltmp2:
.cfi_def_cfa_register %rbp
subq $16, %rsp
xorl %eax, %eax
movl %eax, %edi
movabsq $.L.str, %rsi
movb $0, %al
callq get_string
movabsq $.L.str.1, %rdi
movq %rax, -8(%rbp)
movq -8(%rbp), %rsi
movb $0, %al
callq printf
...これらの命令は下位レベルであり、コンピュータのプロセッサが直接理解できるバイナリ命令に近いものです。バイナリ命令は、変数名のような抽象化ではなく、通常はバイト自体を操作します。 次のステップは、アセンブリコードを取り出し、それをアセンブル してバイナリの命令に変換することです。バイナリ形式の命令はマシンコード と呼ばれ、コンピュータのCPUが直接実行できます。 最後のステップは、cs50.cのように、以前にインクルードしたライブラリをコンパイルしたものを、実際にプログラムのバイナリと結合するリンク です。最終的には、hello.c、cs50.c、stdio.cを組み合わせたマシンコードであるa.outまたはhelloという1つのバイナリファイルになります (CS50 IDEでは、cs50.cとstdio.cのプリコンパイルされたマシンコードがすでにインストールされており、それらを検索して使用するようにclang が設定されています) 。 これらの4つのステップはmakeによって抽象化または単純化されているため、実装する必要があるのはプログラムのコードだけです。 デバッグ
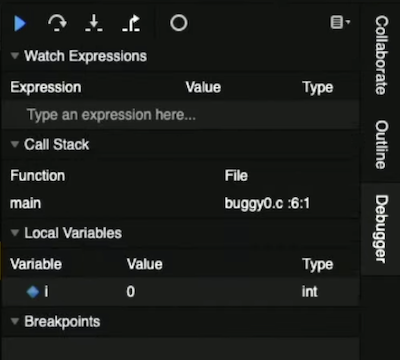
バグ とは、意図した動作とは異なる動作を引き起こすプログラム内の誤りまたは問題です。デバッグとは、これらのバグを見つけて修正するプロセスです。前回、私たちはコンパイルをしたのと同時に、良いスタイルを持ち、正しいコードを書くのに役立ついくつかのツールについて学びました。 別の 「ツール」 であるprintf関数を使用して、デバッグに役立つメッセージと変数を出力できます。 buggy0.cを見てみましょう。#include <stdio.h>
int main(void)
{
// Print 10 hashes
for (int i = 0; i <= 10; i++)
{
printf("#\n");
}
}
10個の#を印刷したいのですが、11個あるようです (プログラムはエラーなしでコンパイルされているので、ロジックにエラーが発生しています) 。何が問題なのかわからない場合は、一時的に別のprintf を追加します。 #include <stdio.h>
int main(void)
{
for (int i = 0; i <= 10; i++)
{
printf("i is now %i\n", i);
printf("#\n");
}
}
これで、iが0から開始して10まで続いていることがわかります。forループを10で停止するため、i <= 10ではなくi < 10とします。 CS50 IDEには、プログラムのデバッグに役立つ別のツールdebug50 gdbと呼ばれる標準ツール上に構築されています。これらのデバッガ はどちらも、プログラムをステップバイステップで実行し、プログラムの実行中に変数やその他の情報を確認できるプログラムです。 debug50 ./buggy0を実行すると、プログラムを変更したので再コンパイルするように指示されます。次に、デバッガがプログラムを一時停止するコードの行にブレークポイント またはインジケータを追加するように指示します。ターミナルで上下キーを使うことで、過去のコマンドを再入力せずに利用できます。 コードの6行目の左側をクリックすると、赤い円が表示されます。 そして、debug50 ./buggy0をもう一度実行すると、右側にデバッガ・パネルが開きます。 作成した変数iがローカル変数 (Local Variables) セクションの下にあり、値が0であることがわかります。 ブレークポイントは6行目でプログラムを一時停止し、その行を黄色で強調表示しています。続行するには、デバッガパネルにいくつかのコントロールがありますが、青い三角形は、別のブレークポイントまたはプログラムの最後に到達するまでプログラムを続行します。右側にあるカーブした矢印 「Step Over」 は、行を 「Step Over (またいで)」 して行を実行し、直後にプログラムを再び一時停止します。 そこで、カーブした矢印を使用して次の行を実行し、その後の変化を確認します。printfの行に戻り、カーブした矢印をもう一度押すと、ターミナルウィンドウに#が1つ表示されます。矢印をもう一度クリックすると、iの値が1に変わります。矢印をクリックし続けると、プログラムが1行ずつ実行されます。 デバッガを終了するには、control + Cを押して実行中のプログラムを停止します。 buggy1.c: 別の例としてbuggy1.cを見てみましょう。#include <cs50.h>
#include <stdio.h>
// Prototype
int get_negative_int(void);
int main(void)
{
// Get negative integer from user
int i = get_negative_int();
printf("%i\n", i);
}
int get_negative_int(void)
{
int n;
do
{
n = get_int("Negative Integer: ");
}
while (n < 0);
return n;
}
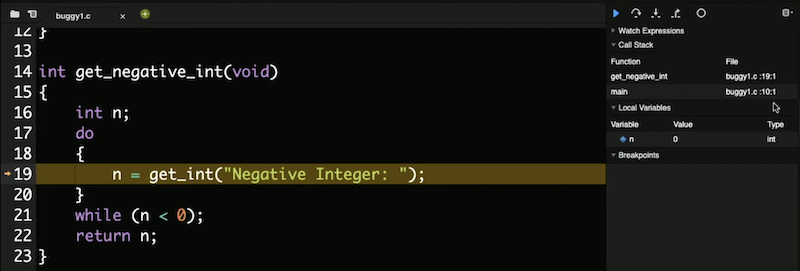
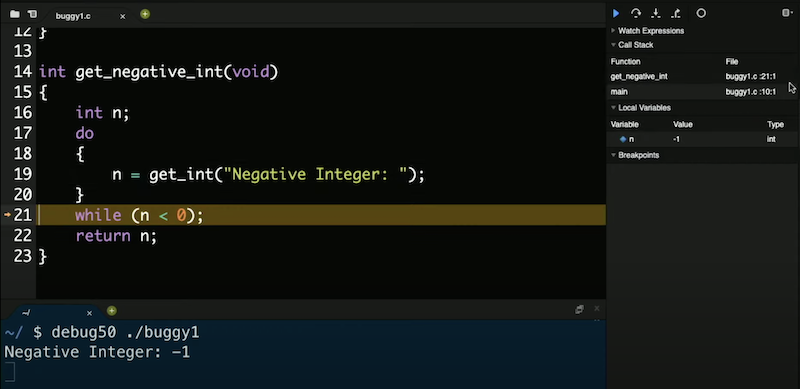
別の関数get_negative_intを実装し、ユーザから負の整数を取得しました。main関数の前にプロトタイプを記述する必要があり、そうすればコードがコンパイルされます。 しかし、プログラムを実行すると、負の整数を指定した後も負の整数を指定するように要求され続けます。行10 int i = get_negative_int();にブレークポイントを設定します。これが最初の興味深いコード行だからです。debug50 ./buggy1を実行し、デバッグパネルの 「コールスタック」 セクションでmain関数にいることを確認します (「コールスタック」 とは、その時点でプログラム内で呼び出され、まだから返されていないすべての関数を指します。これまでは、main関数のみが呼び出されていました) 。 下向きの矢印 「Step Into」 をクリックすると、デバッガがその行で呼び出されている関数get_negative_intの中に (into ) 移動します。コールスタックが関数の名前で更新され、変数nが値0で更新されています。 「Step Over」をもう一度クリックすると、nが-1に更新されています。これは実際に入力した値です。 もう一度 「Step Over」 をクリックすると、プログラムがループ内に戻っているのがわかります。whileループはまだ実行中であるため、whileループがチェックする条件はtrueである必要があります。n < 0は負の整数を入力すると真であるため、n >= 0に変更してバグを修正する必要があります。 debug50の使い方を学ぶために少しの時間を投資することで、将来多くの時間を節約することができます。また、ddb ( 「duck debugger」 の短縮形) を使用することもできます。これは、ラバーダックに何をしようとしているのかを説明するための実際のテクニック であり、多くの場合、ロジックや実装の誤りを理解しながら説明することができます。 メモリ
Cでは、データを格納するために使用できる変数のタイプが異なり、それぞれが一定量のスペースを占有します。コンピュータシステムによって実際に使用される容量は異なりますが、ここではCS50 IDEで使用される容量を使用します。 コンピュータの内部にはRAM(ランダム・アクセス・メモリ )と呼ばれるチップがあります。RAMは、プログラムが実行されている間のコードや、プログラムが開いている間のファイルなど、短期間使用するためのデータを格納します。プログラムやファイルをハードドライブ (またはSSD、ソリッドステートドライブ) に保存して長期保存することもありますが、RAMの方がはるかに高速なので使用します。ただし、RAMは揮発性であるため、データを保存するために電力が必要です。 RAMに格納されたバイトは、グリッドにあるかのように考えることができます。 実際には、チップあたり数百万または数十億バイトです。各バイトはチップ上での位置 (最初のバイト、2番目のバイトなど) に対応します。 Cでは、char型の変数を作成すると、その変数は1バイトのサイズになり、RAM上のこれらのボックスの1つに物理的に格納されます。4バイトの整数は、これらのボックスの4つを占有します。 配列
#include <stdio.h>
int main(void)
{
int score1 = 72;
int score2 = 73;
int score3 = 33;
printf("Average: %f\n", (score1 + score2 + score3) / 3.0);
}
3ではなく3.0で除算するので、結果もfloatになります。プログラムをコンパイルして実行すると、平均値が表示されます。 プログラムの実行中、3つのint変数がメモリに格納されます。 各intは4バイトを表す4つのボックスを持ち、各バイトは8ビットの0、1で構成され、電気部品によって格納されます。 メモリ内では、変数を次々に連続して格納し、ループを使用してより簡単にアクセスできることがわかります。Cでは、連続して格納された値のリストを配列 と呼びます。 上のプログラムでは、int scores[3];によって3つの整数の配列を宣言できます。 また、scores[0] = 72として配列内の変数を割り当てて使用することもできます。大カッコを使用して、配列内の 「0番目」 の位置にインデックスを付けて、その位置に移動します。配列のインデックスは0から始まります。つまり、最初の値のインデックスは0、2番目の値のインデックスは1というようになります。 配列を使用するようにプログラムを更新します。 #include <cs50.h>
#include <stdio.h>
int main(void)
{
int scores[3];
scores[0] = get_int("Score: ");
scores[1] = get_int("Score: ");
scores[2] = get_int("Score: ");
// Print average
printf("Average: %f\n", (scores[0] + scores[1] + scores[2]) / 3.0);
}
ここで、ユーザに3つの値を要求し、前と同じように平均を出力しようと思いますが、配列に格納された値を使用します。 配列内の項目は、その位置に基づいて設定およびアクセスすることができ、その位置は変数の値にもまた なるため、ループを使用できます。 #include <cs50.h>
#include <stdio.h>
int main(void)
{
int scores[3];
for (int i = 0; i < 3; i++)
{
scores[i] = get_int("Score: ");
}
// Print average
printf("Average: %f\n", (scores[0] + scores[1] + scores[2]) / 3.0);
}
ハードコーディング、つまり各要素を3回手動で指定する代わりに、forループとiを配列内の各要素のインデックスとして使用します。 そして、配列の長さを表す値3を2つの異なる場所で繰り返しました。プログラムでは定数 (固定値の変数) を使用できます。 #include <cs50.h>
#include <stdio.h>
const int TOTAL = 3;
int main(void)
{
int scores[TOTAL];
for (int i = 0; i < TOTAL; i++)
{
scores[i] = get_int("Score: ");
}
printf("Average: %f\n", (scores[0] + scores[1] + scores[2]) / TOTAL);
}
constキーワードを使用して、TOTALの値がプログラムによって変更されてはならないことをコンパイラに伝えることができます。そして慣例により、変数の宣言をmain関数の外に置き、その名前を大文字にします。これはコンパイラには必要ありませんが、私たちには、この変数が定数であり、最初から見やすいようにします。しかし、正確に3つの値がなければ、現在の平均は間違っている数値です。 平均を計算する関数を追加します。 float average(int length, int array[])
{
int sum = 0;
for (int i = 0; i < length; i++)
{
sum += array[i];
}
return sum / (float) length;
}
lengthとintの配列 (任意のサイズ) を渡し、ヘルパー関数内で別のループを使用して値を合計して変数sumにします。(float) を使用してlengthをfloatにキャストするので、この2つを分割した結果もfloatになります。main関数では、printf("Average: %f\n", average(TOTAL, scores);を使用して新しいaverage関数を呼び出すことができます。 main内の変数の名前は、値 のみが渡されるため、averageが呼び出すものと一致させる必要はありません。配列の長さをaverage関数に渡しているため、average関数はいくつ値があるか知ることができます。 文字
#include <stdio.h>
int main(void)
{
char c = '#';
printf("%c\n", c);
}
このプログラムを実行すると、ターミナルに#と表示されます。 プログラムを変更してcを整数として出力するとどうなるかを見てみましょう。 #include <stdio.h>
int main(void)
{
char c = '#';
printf("%i\n", (int) c);
}
このプログラムを実行すると、35 が出力されます。実際、35 は#記号のASCIIコードであることがわかります。実際には、cを明示的にintにキャストする必要はありません。この場合、コンパイラーはそれを行うことができます。 charは1バイトなので、上のメモリグリッドの1つのボックスに格納されていると考えることができます。文字列
文字列やテキストを出力するには、文字ごとに変数を作成して出力します。 #include <stdio.h>
int main(void)
{
char c1 = 'H';
char c2 = 'I';
char c3 = '!';
printf("%c%c%c\n", c1, c2, c3);
}
すると、HI! という文字列が表示されます。 次に、各文字の整数値を出力します。 #include <stdio.h>
int main(void)
{
char c1 = 'H';
char c2 = 'I';
char c3 = '!';
printf("%i %i %i\n", c1, c2, c3);
}
72 73 33 が出力され、これらの文字が次のようにメモリに格納されていることがわかります。文字列 は実際には単なる文字の配列であり、CではなくCS50ライブラリで定義されています。sという配列がある場合、各文字はs[0] 、s[1]などでアクセスできます。そして、文字列は特殊文字「\0」、またはすべてのビットが0に設定されたバイトで終わることがわかります。この文字はNULL文字 またはNULと呼ばれます。したがって、実際には、3文字の文字列を格納するために4バイトが必要です。 このプログラムでは、文字列を配列として使用し、文字列の各文字のASCIIコードまたは整数値を出力できます。 #include <cs50.h>
#include <stdio.h>
int main(void)
{
string s = "HI!";
printf("%i %i %i %i\n", s[0], s[1], s[2], s[3]);
}
予想どおり、72 73 33 0が印刷されています。s[4]にアクセスしようとすると、予期しないシンボルが出力されます。Cを使うと、私たちのコードは本来アクセスすべきでないメモリにアクセスしたり変更したりすることができ、これは強力ですが危険です。 ループを使用して、文字列内のすべての文字を出力できます。 #include <cs50.h>
#include <stdio.h>
int main(void)
{
string s = get_string("Input: ");
printf("Output: ");
for (int i = 0; s[i] != '\0'; i++)
{
printf("%c", s[i]);
}
printf("\n");
}
ループの条件を変更して、s[i] != '\0'、つまりsの現在位置にある文字がnull文字でない場合以外という条件だけでなく、iが何であるかにとらわれずループを継続することができます。 Cの文字列 (string) ライブラリstrlenに付属する関数を使用して、ループの文字列の長さを取得できます。 #include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
string s = get_string("Input: ");
printf("Output: ");
for (int i = 0; i < strlen(s); i++)
{
printf("%c", s[i]);
}
printf("\n");
}
プログラムの設計を改善する機会です。この条件では、各文字が出力された後に文字列の長さをチェックするため、ループは少し非効率的です。ただし、文字列の長さは変更されないため、文字列の長さを1回チェックすれば大丈夫です。 #include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
string s = get_string("Input: ");
printf("Output:\n");
for (int i = 0, n = strlen(s); i < n; i++)
{
printf("%c\n", s[i]);
}
}
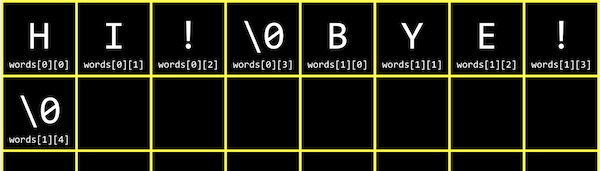
ループの開始時に、変数iと変数nの両方を初期化し、nで文字列の長さを記憶します。これにより、strlenを呼び出して文字列の長さを毎回計算することなく、値を確認できます。nを格納するためにもう少しメモリを使う必要がありましたが、これにより、毎回文字列の長さをチェックする必要がなくなり、時間を節約できます。 次の2つの文字列の配列を宣言します。 string words[2];
words[0] = "HI!";
words[1] = "BYE!";
メモリ内では、文字列の配列は次のように格納され、アクセスされます。 words[0]は、文字列であるwords配列の最初の要素または値を参照するため、words[0][0]は、文字であるその文字列の最初の要素を参照します。これまで見てきたものを組み合わせて、文字を大文字にするプログラムを書くことができます。 #include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
string s = get_string("Before: ");
printf("After: ");
for (int i = 0, n = strlen(s); i < n; i++)
{
if (s[i] >= 'a' && s[i] <= 'z')
{
printf("%c", s[i] - 32);
}
else
{
printf("%c", s[i]);
}
}
printf("\n");
}
まず、ユーザから文字列sを取得します。次に、文字列内の各文字が小文字の場合 (つまり、aとzの間の値を持つ場合) 、大文字に変換します。それ以外の場合は、そのまま表示するだけです。ASCII値の差を引くことで、小文字を大文字に変換できます (小文字は大文字よりも高いASCII値を持ち、同じ文字間の違いは同じ値であることがわかっているので、小文字から大文字を引くことができます) 別のライブラリctype.hを使用することもできます。 #include <cs50.h>
#include <ctype.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
string s = get_string("Before: ");
printf("After: ");
for (int i = 0, n = strlen(s); i < n; i++)
{
if (islower(s[i]))
{
printf("%c", toupper(s[i]));
}
else
{
printf("%c", s[i]);
}
}
printf("\n");
}
他の人がこの関数を書いてテストしてくれたので、コードは読みやすくなり、正確になりそうです。 さらに単純化して、各文字をtoupperに渡すだけで、小文字以外の文字は変更されません。 #include <cs50.h>
#include <ctype.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
string s = get_string("Before: ");
printf("After: ");
for (int i = 0, n = strlen(s); i < n; i++)
{
printf("%c", toupper(s[i]));
}
printf("\n");
}
CS50のマニュアルページ toupper() は、とりわけctypeと呼ばれるライブラリーから使用できる関数です。 コマンドライン引数
独自のプログラムは、コマンドライン引数、つまりプログラム名の後に追加された単語をコマンド自体に取り込むこともできます。 argv.cでは、main関数の外観を次のように変更します。#include <cs50.h>
#include <stdio.h>
int main(int argc, string argv[])
{
if (argc == 2)
{
printf("hello, %s\n", argv[1]);
}
else
{
printf("hello, world\n");
}
}
argcとargvは2つの変数で、プログラムをコマンドラインから実行したときにmain関数が自動的に取得するようになりました。argcは引数の数 です。argvは引数ベクトル (引数リスト) で、文字列の配列です。最初の引数argv[0]はプログラムの名前です (例えば./helloなどの最初にタイプされた単語)。この例では、引数が2つあるかどうかをチェックし、2番目の引数がある場合は出力します。 たとえば、./argv Davidを実行すると、hello, Davidと表示されます。コマンドの2番目の単語としてDavidと入力したためです。 各文字を個別に印刷することもできます。 #include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(int argc, string argv[])
{
if (argc == 2)
{
for (int i = 0, n = strlen(argv[1]); i < n; i++)
{
printf("%c\n", argv[1][i]);
}
}
}
argv[1][i]を使用して、プログラムの最初の引数の各文字にアクセスします。main関数も整数値を返すことがわかりました。デフォルトでは、main関数は何も問題がないことを示す0を返しますが、別の値を返すプログラムを作成することもできます。#include <cs50.h>
#include <stdio.h>
int main(int argc, string argv[])
{
if (argc != 2)
{
printf("missing command-line argument\n");
return 1;
}
printf("hello, %s\n", argv[1]);
return 0;
}
プログラムのmain の戻り値は終了コード と呼ばれ、通常はエラーコードを示すために使用されます (ここでは、プログラムの最後に明示的にreturn 0を記述しますが、本来は必要ありません) 。 複雑なプログラムを作成する場合、このようなエラーコードは、ユーザーには表示されていない場合や意味がない場合でも、問題の原因を特定するのに役立ちます。 アプリケーション
プログラムの中で文字列を扱う方法や、ライブラリの中で他の人によって書かれたコードを扱う方法がわかった今、単語や文の長さや複雑さなどの要因に基づいて、テキストの段落を読みやすさのレベルで分析することができます。 暗号技術 は、情報をスクランブルしたり、隠したりする技術です。誰かにメッセージを送信したい場合は、暗号化 するか、何らかの方法でメッセージをスクランブルして、他の人が読みにくいようにします。このアルゴリズムに入力される元のメッセージは平文 と呼ばれ、暗号化されたメッセージは暗号文 と呼ばれます。スクランブルを行うアルゴリズムは暗号 と呼ばれます。暗号は一般に平文に加えて別の入力を必要とします。キー は、数字のように、秘密にされている他の入力です。たとえば、I L O V E Y O Uのようなメッセージを送信する場合、最初にASCII: 73 76 79 86 69 89 79 85に変換します。次に、単に1のキーと簡単なアルゴリズムを使用して暗号化し、各値に74 77 80 87 70 90 80 86とキーを足します。値をASCIIに変換した後の暗号文はJ M P W F Z P Vになります。これを復号化するには、キーが1であることを知っていて、各文字からそれを減算する必要があります。 これらの概念は、後段のレッスンと問題セットで説明します。