16進数
- Week 2では、メモリと、各バイトがどのようにアドレスまたは識別子を持っているかについて話し、データが実際に格納されている場所を参照できるようにしました。
- 慣習的に、メモリのアドレスは16進法を使っていることが分かっています。16進数は、0-9、A-Fを使った16の数字で構成されていて、A-Fは10-15を表しています。
- 2桁の16進数を考えてみましょう。
16^1 16^0
0 A- ここでは、 (16^0=1であるため) 1の位のAの10進数は10です。
0F(10進数で15に相当) までカウントできます。 0Fの後は、10進数で09から10を表すように、1を繰り上げる必要があります。
16^1 16^0
1 0- ここで、
1の値は 16^1*1=16 なので、16進数の10は10進数で言うところの16になります。
- 2桁の場合、
FFの最大値、すなわち16^1*15+16^0*15=240+15=255を得ることができ、これは8ビットの2進数と同じ最大値です。したがって、16進数の2桁は、1バイトの値を2進数で表すのに便利です (16の値を持つ16進数の各桁は、2進数の4ビットにマッピングされます) 。 - 文書では値が16進数であることを示すために
0xで始まり、0x10の場合であれば10進数の10ではなく16であり、16進数としての10であることを示します。 - RGBカラーシステムでは、従来、各カラーの量を16進数で表していました。たとえば、16進数の
000000は、赤、緑、青のそれぞれに対して0を表し、組み合わさった黒がその色になります。FF0000だと赤色の最大値255になります。FFFFFFは各色の最大値を示し、組み合わされうと最も明るい白になります。色ごとに異なる値を使用すると、何百万もの異なる色を表現できます。 - コンピュータのメモリについても、アドレスまたは場所ごとに16進数を使用します。
アドレス
- 値
nを作成して出力します。
#include <stdio.h>
int main(void)
{
int n = 50;
printf("%i\n", n);
}
- コンピュータのメモリには、50を2進数(ビット列)で格納した4バイトがどこかにあり、nと名前付けされています。

- メモリは何十億バイトもあるので、変数
nのバイトは0x12345678のようなどこかから始まることがわかります。 - Cでは、実際には
&演算子でアドレスを確認できます。これは、 「この変数のアドレスを取得する」 ことを意味します。
#include <stdio.h>
int main(void)
{
int n = 50;
printf("%p\n", &n);
}%pはアドレスの書式コードです。- CS50 IDEでは、
0x7ffd80792f7cのようなアドレスが表示されます。アドレスの値自体は、変数が格納されているメモリ内の単なる場所であるため、有用ではありません。このアドレスを後で使用できるようにすることが重要です。
- CS50 IDEでは、
*演算子 (間接参照演算子) を使用すると、ポインタが指している場所に 「行く」事ができます。- たとえば、
*&nを出力するとした時は、nのアドレスに 行き、 アドレスnの値である50が出力されます。
#include <stdio.h>
int main(void)
{
int n = 50;
printf("%i\n", *&n);
}ポインタ
- アドレスを格納する変数はポインタと呼ばれ、メモリ内の場所を 「参照する」 値と考えることができます。Cでは、ポインタは特定の型の値を参照できます。
*演算子を (残念ながら紛らわしい方法で) 使用して、ポインタにしたい変数を宣言することができます。
#include <stdio.h>
int main(void)
{
int n = 50;
int *p = &n;
printf("%p\n", p);
}- ここでは、
int *pを使用して、整数であるint型へのポインタを宣言します。次に、その値 (アドレス0x12345678など) をprintf("%p\n", *p);で出力しています。
- コンピュータのメモリでは、変数は次のようになります。
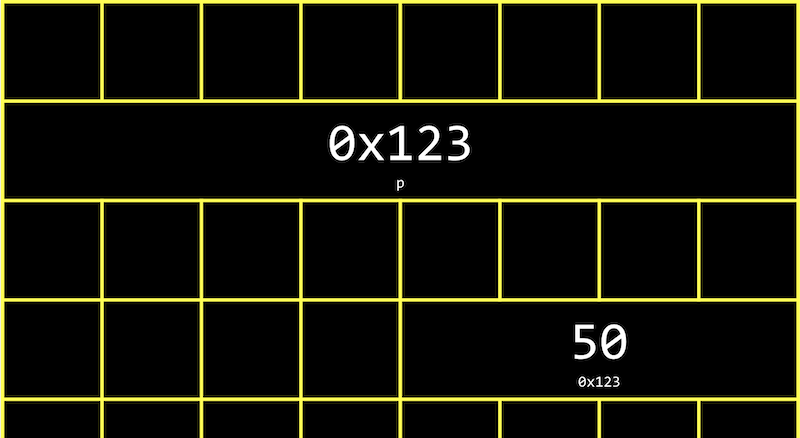
pは変数自体なので、メモリのどこかにあり、そこに格納されている値はnのアドレスです。- 最近のコンピュータシステムは 「64ビット」 です。つまり、メモリのアドレス指定に64ビットを使用するので、ポインタは実際には8バイトになり、4バイトの整数の2倍の大きさになります。
- アドレスの実際の値を抽象化することができます。なぜなら、プログラムで変数を宣言するときにはアドレスは異なり、あまり有用ではなく、単に p はある値を 「指し示す」、「参照する」 と考えるからです。
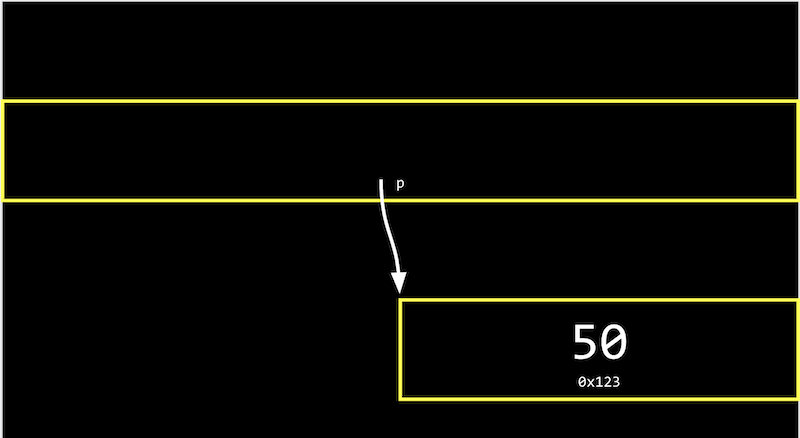
- 現実の世界では、アドレス付きの多くのメールボックスの中に 「p」 というラベルの付いたメールボックスがある場合があります。メールボックスの中には
0x123のような値を入れることができます。これは他のメールボックスnのアドレスで、アドレスは0x123です。
文字列
string s = "HI!"; と宣言された変数は一度に1文字ずつメモリに格納されます。s[0] 、s[1] 、s[2] 、s[3] を使って各文字にアクセスできます。

しかし、それぞれの文字はメモリに格納されているため、それぞれが固有のアドレスを持ち、s は実際には最初の文字のアドレスを持つ単なるポインタであることがわかります。

変数sには、文字列の最初の文字のアドレスが格納されます。値 \0 は、文字列の末尾を示す唯一のインジケータです。

- 残りの文字は連続した配列ですから、
sのアドレスから始めて、\0に達するまでメモリから一度に1文字ずつ読み続けることができます。 - 文字列を出力しましょう。
#include <cs50.h>
#include <stdio.h>
int main(void)
{
string s = "HI!";
printf("%s\n", s);
}•s に格納された値は printf("%p\n", s); で、文字列の最初の文字のアドレスをメモリに出力しているので、0x4006a4 のように表示されます。
•printf("%p\n", &s[1]); で別の行を追加すると、メモリ内の次のアドレス 0x4006a5 が表示されます。
•文字列 s はメモリ上のある文字へのポインタであることがわかります。
•実際、CS50ライブラリでは、Cでは存在しない string という型を char * として typedef char *string; で定義しています。カスタム型stringは、typedefで単なるchar *として定義されます。したがって、string s = "HI!" は char *s = "HI!"; と同じです。また、char * を使用することで、CS50ライブラリがない場合とまったく同じ方法でCの文字列を使用できます。
ポインタ演算
•ポインタ演算とは、ポインタを使ってアドレスに対し数学的演算を行うことです。
•文字列の各文字を出力することができます ( char * を直接使用)
#include <stdio.h>
int main(void)
{
char *s = "HI!";
printf("%c\n", s[0]);
printf("%c\n", s[1]);
printf("%c\n", s[2]);
}- アドレスを直接指定することもできます。
#include <stdio.h>
int main(void)
{
char *s = "HI!";
printf("%c\n", *s);
printf("%c\n", *(s+1));
printf("%c\n", *(s+2));
}*sはsに格納されているアドレスに、*(s+1)は1バイト上位のアドレス、つまり次の文字を持つメモリ内の場所を参照します。s[1]は*(s+1)の糖衣構文で、機能的には同じですが、人間にとっては読み書きしやすいものです。*(s+10000)のように、メモリ内のアクセスするべきではないアドレスにアクセスすることもできます。プログラムを実行すると、セグメンテーション違反が発生したり、プログラムが不要なセグメントのメモリにアクセスした結果クラッシュしたりします。
比較とコピー
- ユーザ入力からの2つの整数を比較してみましょう。
#include <cs50.h>
#include <stdio.h>
int main(void)
{
int i = get_int("i: ");
int j = get_int("j: ");
if (i == j)
{
printf("Same\n");
}
else
{
printf("Different\n");
}
}- プログラムをコンパイルして実行すると、予想どおりに動作し、2つの整数が同じ値であれば 「Same (同じ)」 、異なる値であれば 「Different (異なる)」 と表示されます。
- 2つの文字列を比較しようとすると、同じ入力でもプログラムが 「Different」 と出力していることがわかります。
#include <cs50.h>
#include <stdio.h>
int main(void)
{
char *s = get_string("s: ");
char *t = get_string("t: ");
if (s == t)
{
printf("Same\n");
}
else
{
printf("Different\n");
}
}- 入力が同じでも、 「Different」 と表示されます。
- 各 「文字列」 は、メモリ内の異なる場所へのポインタ
char *です。各文字列の最初の文字が格納されます。したがって、文字列内の文字が同じであっても、常に 「異なる」 と表示されます。
- 各 「文字列」 は、メモリ内の異なる場所へのポインタ
- たとえば、最初の文字列はアドレス0x123 、2番目の文字列は 0x456 、
sはその場所を示す値0x123、tは別の場所を示す値0x456になります。
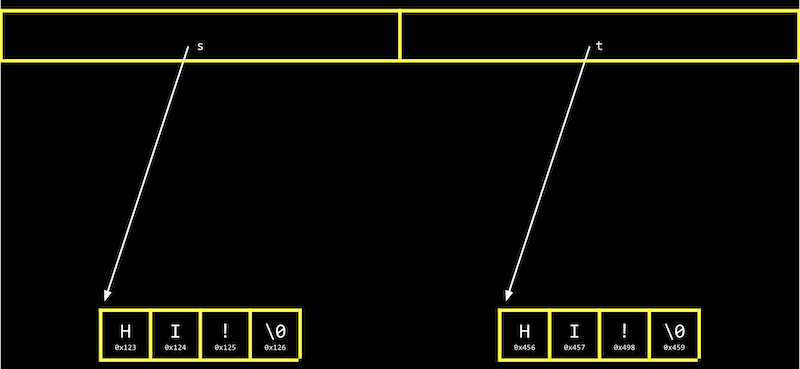
- そして
get_stringは、これまでずっとchar *、すなわちユーザからの文字列の最初の文字へのポインタだけを返してきました。get_stringを2回呼び出したため、2つの異なるポインタが返されました。 - 文字列をコピーしてみましょう。
#include <cs50.h>
#include <ctype.h>
#include <stdio.h>
int main(void)
{
char *s = get_string("s: ");
char *t = s;
t[0] = toupper(t[0]);
printf("s: %s\n", s);
printf("t: %s\n", t);
}- 文字列
sを取得し、sの値をtにコピーします。次に、tの最初の文字を大文字にします。- しかし、プログラムを実行すると、
sとtの両方が大文字になっています。
sとtに同じ値または同じアドレスを設定したので、両方とも同じ文字を指しているため、メモリ内で同じ文字を大文字にしました。
- しかし、プログラムを実行すると、
- 実際に文字列のコピーを作成するには、もう少し作業を行い、
sの各文字をメモリ内の別の場所にコピーする必要があります。
#include <cs50.h>
#include <ctype.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char *s = get_string("s: ");
char *t = malloc(strlen(s) + 1);
for (int i = 0, n = strlen(s); i < n + 1; i++)
{
t[i] = s[i];
}
t[0] = toupper(t[0]);
printf("s: %s\n", s);
printf("t: %s\n", t);
}char *型の新しい変数tをchar *tで作成します。次に、文字列のコピーを保存するのに十分な大きさの新しいメモリ領域を参照します。mallocでは、 (他の値を格納するために使用されていない) メモリ内のバイト数を割り当て、使用する分だけのバイト数を渡します。sの長さはすでにわかっているので、終端のヌル文字の長さに1を加えます。したがって、コードの最終行はchar *t = malloc(strlen(s) + 1);となります。- 次に、
forループを使用して各文字を1つずつコピーします。i < n + 1を使用するのは、実際に文字列の長さであるnまで行って、文字列内の終了文字を確実にコピーするためです。ループ内でt[i] = s[i]を設定し、文字をコピーします。同じ効果を得るために、*(t+i) = *(s+i)を使用することもできますが、読みやすさが劣ることは間違いありません。
- これで、
tの最初の文字だけを大文字にできます。
- 次に、
- プログラムにエラーチェックを追加できます。
#include <cs50.h>
#include <ctype.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char *s = get_string("s: ");
char *t = malloc(strlen(s) + 1);
if (t == NULL)
{
return 1;
}
for (int i = 0, n = strlen(s); i < n + 1; i++)
{
t[i] = s[i];
}
if (strlen(t) > 0)
{
t[0] = toupper(t[0]);
}
printf("s: %s\n", s);
printf("t: %s\n", t);
free(t);
}- コンピュータのメモリが不足している場合、
mallocはNULL(NULLポインタ、参照するアドレスがないことを示す特別な値) を返します。その場合を調べ、tがNULLならば終了します。- 最初の文字を大文字にする前に、
tが長さを持っていることをチェックすることもできます。
- 最後に、前に割り当てたメモリを解放し、他のプログラムが再び使用できるようにします。
free関数を呼び出し、ポインタtを渡します。これでメモリの(整地)チャンクは終了です (get_stringも、mallocを呼び出して文字列にメモリを割り当て、main 関数が戻る直前にfreeを呼び出します) 。
- 最初の文字を大文字にする前に、
- 実際にはループの代わりに、Cの文字列ライブラリにある
strcpy関数を sstrcpy(t, s);として利用し、文字列sをtにコピーします。
valgrind (ヴァルグリンド)
valgrindは、プログラムを実行し、メモリリークが発生していないか、解放せずに割り当てたメモリがあるかどうかを確認するために使用できるコマンドラインツールです。メモリリークにより、最終的にコンピュータのメモリが不足する可能性があります。memory.cでは、文字列を作成しますが、メモリに必要な量よりも少ない割り当てを行います。
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char *s = malloc(3);
s[0] = 'H';
s[1] = 'I';
s[2] = '!';
s[3] = '\0';
printf("%s\n", s);
}- 割り当てたメモリも解放しません。
- コンパイル後に
valgrind ./memoryを実行すると、多くの出力が表示されますが、help50 valgrind ./memoryを実行して、これらのメッセージの一部を説明します。このプログラムでは、 「Invalid write of size 1」 、 「Invalid read of size 1」 、そして最後に 「3 bytes in 1 blocks are definitely lost」 のような断片があり、近くに行番号があります。実際、メモリにs[3]を書き込みますが、これは最初にsに割り当てた内容の一部ではありません。また、sを印刷するときには、s[3]までのすべての部分を読むことになります。最後に、sはプログラムの終了時に解放されません。
- コンパイル後に
- 適切なバイト数を割り当て、最後にメモリを解放することができます。
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
char *s = malloc(4);
s[0] = 'H';
s[1] = 'I';
s[2] = '!';
s[3] = '\0';
printf("%s\n", s);
free(s);
}valgrindは警告メッセージを表示しません。
ゴミの値
- 以下を見てみましょう。
int main(void)
{
int *x;
int *y;
x = malloc(sizeof(int));
*x = 42;
*y = 13;
y = x;
*y = 13;
}- 整数
xとyへの2つのポインタを宣言しますが、それらに値を割り当てません。mallocを使ってsizeof(int)を持つ整数に十分なメモリを割り当て、それをxに格納します。*x = 42は、xが指すアドレスに行き、メモリ内のその位置の値を42に設定します。*y = 13で、yが指すアドレスに値13を配置しようとしています。しかし、yに値を代入したことがないので、これまでコンピュータで実行されていたプログラムからのゴミの値やメモリ内の未知の値があります。したがって、アドレスとして y のゴミの値を参照しにいこうとすると、不明なアドレスを参照しようとすることになり、セグメンテーション違反 (segfault)が発生する可能性があります。
- Pointer Fun with Binkyという動画で、上のコードのコンセプトを紹介しています。
- 配列を宣言し、その値を設定しないことで、不要な値を出力することができます。
#include <stdio.h>
int main(void)
{
int scores[3];
for (int i = 0; i < 3; i++)
{
printf("%i\n", scores[i]);
}
}- このプログラムをコンパイルして実行すると、さまざまな値が表示されます。
スワップ
- 2つの整数の値を入れ替えてみましょう。
#include <stdio.h>
void swap(int a, int b);
int main(void)
{
int x = 1;
int y = 2;
printf("x is %i, y is %i\n", x, y);
swap(x, y);
printf("x is %i, y is %i\n", x, y);
}
void swap(int a, int b)
{
int tmp = a;
a = b;
b = tmp;
}- 現実の世界では、1つのグラスに赤い液体が入っていて、別のグラスに青い液体が入っていて、それらを交換したい場合、液体の1つ (おそらく赤いグラス) を一時的に保持するために3番目のグラスが必要になります。青い液体を最初のグラスに注ぎ、最後に赤い液体を一時的なグラスから2番目のグラスに注ぎます。
swap関数には、一時記憶領域として使用する第3の変数があります。tmpにaを入れ、aをbの値に設定し、最後にbをaの元の値に変更することができます。
- しかし、この関数をプログラムで使用しようとしても、何も変更はありません。
swap関数は、渡されたときに独自の変数aとb(xとyのコピー) を取得するため、これらの値を変更してもメイン関数のxとyは変更されません。
メモリレイアウト
- コンピュータのメモリ内では、プログラム用に格納する必要があるさまざまなタイプのデータが、さまざまなセクションに編成されています。
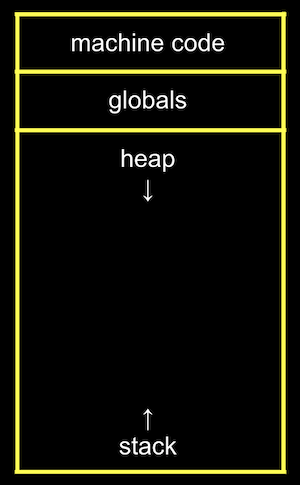
- 機械語セクションは、コンパイルされたプログラムのバイナリコードです。プログラムを実行すると、そのコードがメモリの 「トップ」 にロードされます。
- すぐ下、メモリの次の部分には、プログラムで宣言したグローバル変数が配置されます。
- ヒープセクションは、
mallocがプログラムで使用するための空きメモリを取得できる空の領域です。mallocを呼び出すと、トップダウンでメモリの割り当てを開始します。
- スタックセクションは、呼び出されたプログラム内の関数によって使用され、上に向かって成長します。たとえば、
main関数はスタックの一番下にあり、ローカル変数xとyを持っています。スワップ関数は、呼び出されるとmainの上に独自のメモリ領域を持ち、ローカル変数a、b、およびtmpを持ちます。

- 関数
swapが終了すると、使用していたメモリは次の関数呼び出しのために解放されます。xとyは引数であるため、swapにaとbとしてコピーされるため、変更がmainに反映されることはありません。 xとyのアドレスを渡すことで、swap関数は実際に動作します。
#include <stdio.h>
void swap(int *a, int *b);
int main(void)
{
int x = 1;
int y = 2;
printf("x is %i, y is %i\n", x, y);
swap(&x, &y);
printf("x is %i, y is %i\n", x, y);
}
void swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}xとyのアドレスはmainから&xと&yとswapして渡され、int *a構文を使ってswap関数がポインタを取ることを宣言します。xの値をポインタaに従ってtmpに保存し、yの値をポインタbに従って取得して、aが指している場所 (x) に保存します。最後に、tmpの値をb(y) が指す場所に格納します。

- 大量のメモリを確保する
mallocを呼び出すと、ヒープオーバーフローしてしまいます。あるいは、関数から復帰せずに呼び出した関数が多すぎると、スタックに割り当てられたメモリが多すぎるスタックオーバーフローが発生します。 - 関数を呼び出して、マリオのピラミッドを描画します。
#include <cs50.h>
#include <stdio.h>
void draw(int h);
int main(void)
{
int height = get_int("Height: ");
draw(height);
}
void draw(int h)
{
for (int i = 1; i <= h; i++)
{
for (int j = 1; j <= i; j++)
{
printf("#");
}
printf("\n");
}
}drawを再帰的に利用できます。
void draw(int h)
{
draw(h - 1);
for (int i = 0; i < h; i++)
{
printf("#");
}
printf("\n");
}makeを使用してこれをコンパイルしようとすると、draw関数が停止せずに再帰的に呼び出されるという警告が表示されます。このため、追加のチェックを行わずにclangを使用します。このプログラムを実行すると、すぐにセグメンテーション違反が発生します。drawが何度も呼び出され、スタックのメモリが足りなくなりました。- 基本ケースを追加すると、
draw関数はある時点で自身を呼び出さなくなります。
void draw(int h)
{
if (h == 0)
{
return;
}
draw(h - 1);
for (int i = 0; i < h; i++)
{
printf("#");
}
printf("\n");
}- しかし、
2000000000のように高さに大きな値を入力した場合、draw を何度も呼び出しても終了しないため、メモリが不足します。 - バッファオーバーフローは、、配列のように割り当てたメモリの領域であるバッファの末尾を超え、存在すべきでないメモリへのアクセスを行うと発生します。
scanf
- Cライブラリ関数
scanfを使ってget_intを実装することができます。
#include <stdio.h>
int main(void)
{
int x;
printf("x: ");
scanf("%i", &x);
printf("x: %i\n", x);
}scanfはフォーマット%iを取り、入力はそのフォーマットのために 「スキャン」 されます。また、メモリー内のアドレスを渡して、そのアドレスに入力を渡します。しかし、scanfにはエラーチェック機能があまりないため、整数を取得できない場合があります。- 同じ方法で文字列を取得できます。
#include <stdio.h>
int main(void)
{
char *s;
printf("s: ");
scanf("%s", s);
printf("s: %s\n", s);
}- しかし、実際には
sにメモリを割り当てていないので、mallocを呼び出して文字列にメモリを割り当てる必要があります。char s[4];を使用して4文字の配列を宣言します。次に、s はscanfとprintfの最初の文字へのポインタとして扱われます。- これで、ユーザが長さ3以下の文字列を入力しても、プログラムは安全に動作します。しかし、ユーザが長い文字列を入力すると、
scanfは配列の終端を越えて未知のメモリに書き込もうとし、プログラムをクラッシュさせてしまうかもしれません。
- CS50ライブラリの
get_stringは、scanfがより多くの文字を読み込むときにより多くのメモリを継続的に割り当てるため、この問題は発生しません。
- これで、ユーザが長さ3以下の文字列を入力しても、プログラムは安全に動作します。しかし、ユーザが長い文字列を入力すると、
ファイル
- ポインタを使用する機能により、デジタル電話帳などのファイルを開くこともできます。
#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
FILE *file = fopen("phonebook.csv", "a");
if (file == NULL)
{
return 1;
}
char *name = get_string("Name: ");
char *number = get_string("Number: ");
fprintf(file, "%s,%s\n", name, number);
fclose(file);
}fopenは、ファイルを開くために使用できる新しい関数です。この関数は、読み書きできる新しい型FILEへのポインタを返します。最初の引数はファイル名で、2番目の引数はファイルを開くモード (rは読み取り用、wは書き込み用、aは追加用) です。- 何らかの理由でファイルを開けなかった場合に終了するチェックを追加します。
- 文字列を取得したら、
fprintfを使ってファイルに出力できます。
- 最後に、
fcloseを使用してファイルを閉じます。
- これで、カンマ区切り値 (ミニスプレッドシートなど) の独自のCSVファイルをプログラムで作成できます。
グラフィックス
- バイナリ形式で読み取り、ピクセルや色にマッピングして、画像やビデオを表示できます。ただし、イメージファイル内のビット数が限られている場合は、個々のピクセルが表示される前に拡大するしかありません。
- しかし、人工知能と機械学習を使えば、他のデータに基づいて推測することで、以前にはなかった追加の詳細を生成できるアルゴリズムを使用できます。
- ファイルを開き、それがJPEGファイルかどうか、特定の形式のイメージファイルかどうかを示すプログラムを見てみましょう。
#include <stdint.h>
#include <stdio.h>
typedef uint8_t BYTE;
int main(int argc, char *argv[])
{
// Check usage
if (argc != 2)
{
return 1;
}
// Open file
FILE *file = fopen(argv[1], "r");
if (!file)
{
return 1;
}
// Read first three bytes
BYTE bytes[3];
fread(bytes, sizeof(BYTE), 3, file);
// Check first three bytes
if (bytes[0] == 0xff && bytes[1] == 0xd8 && bytes[2] == 0xff)
{
printf("Maybe\n");
}
else
{
printf("No\n");
}
// Close file
fclose(file);
}
- 最初に、
BYTE を8ビットとして定義し、Cでバイトをより簡単に型として参照できるようにします。- その後、ファイルをオープンし (実際にNULLでないファイルが返ってくることを確認します) 、
fread を使ってファイルの最初の3バイトを bytes というバッファに読み込みます。
- 最初の3バイト (16進数) とJPEGファイルの開始に必要な3バイトを比較できます。これらが同じ場合、ファイルはJPEGファイルである可能性が高くなります (他の種類のファイルでも、これらのバイトで始まる場合があります)。ただし、両者が同じでない場合は、JPEGファイルでないことは明らかです。
- ファイルを自分で1バイトずつコピーすることもできます。
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
typedef uint8_t BYTE;
int main(int argc, char *argv[])
{
// Ensure proper usage
if (argc != 3)
{
fprintf(stderr, "Usage: copy SOURCE DESTINATION\n");
return 1;
}
// open input file
FILE *source = fopen(argv[1], "r");
if (source == NULL)
{
printf("Could not open %s.\n", argv[1]);
return 1;
}
// Open output file
FILE *destination = fopen(argv[2], "w");
if (destination == NULL)
{
fclose(source);
printf("Could not create %s.\n", argv[2]);
return 1;
}
// Copy source to destination, one BYTE at a time
BYTE buffer;
while (fread(&buffer, sizeof(BYTE), 1, source))
{
fwrite(&buffer, sizeof(BYTE), 1, destination);
}
// Close files
fclose(source);
fclose(destination);
return 0;
}
argv は引数を取得するために使用します。引数はファイル名として使用し、ファイルを開いて読み書きします。- その後、
source ファイルから1バイトをバッファに読み込み、そのバイトを destination ファイルに書き込みます。while ループを使用してfreadを呼び出すことができ、読み込むバイトがなくなると fread は停止します。
- これらの機能を使用して、ファイルの読み取りと書き込み、ファイルからのイメージのリカバリ、イメージ内のバイトを変更することによるイメージへのフィルタの追加を、今回の問題セットで行うことができます。
- しかし、人工知能と機械学習を使えば、他のデータに基づいて推測することで、以前にはなかった追加の詳細を生成できるアルゴリズムを使用できます。
#include <stdint.h>
#include <stdio.h>
typedef uint8_t BYTE;
int main(int argc, char *argv[])
{
// Check usage
if (argc != 2)
{
return 1;
}
// Open file
FILE *file = fopen(argv[1], "r");
if (!file)
{
return 1;
}
// Read first three bytes
BYTE bytes[3];
fread(bytes, sizeof(BYTE), 3, file);
// Check first three bytes
if (bytes[0] == 0xff && bytes[1] == 0xd8 && bytes[2] == 0xff)
{
printf("Maybe\n");
}
else
{
printf("No\n");
}
// Close file
fclose(file);
}BYTE を8ビットとして定義し、Cでバイトをより簡単に型として参照できるようにします。- その後、ファイルをオープンし (実際にNULLでないファイルが返ってくることを確認します) 、
freadを使ってファイルの最初の3バイトをbytesというバッファに読み込みます。
- 最初の3バイト (16進数) とJPEGファイルの開始に必要な3バイトを比較できます。これらが同じ場合、ファイルはJPEGファイルである可能性が高くなります (他の種類のファイルでも、これらのバイトで始まる場合があります)。ただし、両者が同じでない場合は、JPEGファイルでないことは明らかです。
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
typedef uint8_t BYTE;
int main(int argc, char *argv[])
{
// Ensure proper usage
if (argc != 3)
{
fprintf(stderr, "Usage: copy SOURCE DESTINATION\n");
return 1;
}
// open input file
FILE *source = fopen(argv[1], "r");
if (source == NULL)
{
printf("Could not open %s.\n", argv[1]);
return 1;
}
// Open output file
FILE *destination = fopen(argv[2], "w");
if (destination == NULL)
{
fclose(source);
printf("Could not create %s.\n", argv[2]);
return 1;
}
// Copy source to destination, one BYTE at a time
BYTE buffer;
while (fread(&buffer, sizeof(BYTE), 1, source))
{
fwrite(&buffer, sizeof(BYTE), 1, destination);
}
// Close files
fclose(source);
fclose(destination);
return 0;
}argv は引数を取得するために使用します。引数はファイル名として使用し、ファイルを開いて読み書きします。- その後、
sourceファイルから1バイトをバッファに読み込み、そのバイトをdestinationファイルに書き込みます。whileループを使用してfreadを呼び出すことができ、読み込むバイトがなくなるとfreadは停止します。