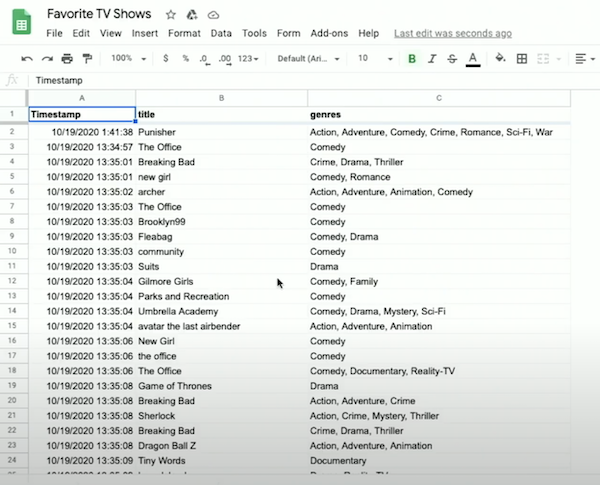
import csv
titles = set()
with open("Favorite TV Shows - Form Responses 1.csv", "r") as file:
reader = csv.DictReader(file)
for row in reader:
titles.add(row["title"])
for title in titles:
print(title)
import csv
titles = {}
with open("Favorite TV Shows - Form Responses 1.csv", "r") as file:
reader = csv.DictReader(file)
for row in reader:
title = row["title"].strip().upper()
if title not in titles:
titles[title] = 0
titles[title] += 1
for title in sorted(titles):
print(title, titles[title])
ここではまず、そのタイトルを見たことがないかどうかをチェックします(not in titles)。もし見ていないのであれば初期値を0に設定し、その後は毎回安全に1ずつ値を増やしていきます。
import csv
title = input("Title: ").strip().upper()
with open("Favorite TV Shows - Form Responses 1.csv", "r") as file:
reader = csv.DictReader(file)
counter = 0
for row in reader:
if row["title"].strip().upper() == title:
counter += 1
print(counter)
SELECT Timestamp, title FROM shows;で複数のカラムを選択することもできます (TimestampはCSVで大文字にされています) 。またはSELECT * FROM shows;ですべての列を表示できます。
SQLは、データのカウントとサマリに使用できる多くの関数をサポートしています。
AVG
COUNT
DISTINCT: 重複のない個別の値を取得
LOWER
MAX
MIN
UPPER
…
以前と同じようにタイトルを大文字に変換してクリーンアップし、一意の値のみを出力できます。
sqlite> SELECT DISTINCT(UPPER(title)) FROM shows;
title
...
"GREY'S ANATOMY"
"SCOOBY DOO"
"MADAM SECRETARY"
クエリを変更する句を追加することもできます。
WHERE: 厳密な条件一致(完全一致)
LIKE: あいまいな条件一致(部分一致、前方一致、後方一致)
ORDER BY: 結果を並べ替える
LIMIT: 結果数の制限(結果の行数の制限)
GROUP BY: 結果をグループ化する
…
タイトルで行をフィルタしてみましょう。
sqlite> SELECT title FROM shows WHERE title = "The Office";
title
...
"The Office"
"The Office"
"The Office"
しかし、他にも検索したいエントリがあるので、以下を使用します。
sqlite> SELECT title FROM shows WHERE title LIKE "%Office%";
title
...
office
"The Office"
"the office "
"The Office"
文字%は、0個以上の他の文字のプレースホルダです。
タイトルで並べ替えできます。
sqlite> SELECT DISTINCT(UPPER(title)) FROM shows ORDER BY UPPER(title);
...
X-FILES
"ZETA GUNDAM"
"ZONDAG MET LUBACH"
同じタイトルを一括りにして、表示される回数を数えることもできます。
sqlite> SELECT UPPER(title), COUNT(title) FROM shows GROUP BY UPPER(title);
...
"THE OFFICE",23
...
"TOP GEAR",1
...
"TWIN PEAKS",4
...
回数で並べ替えできます。
sqlite> SELECT UPPER(title), COUNT(title) FROM shows GROUP BY UPPER(title) ORDER BY COUNT(title);
...
"THE OFFICE",23
FRIENDS,26
"GAME OF THRONES",33
最後にDESC を追加すると、結果が降順で表示されます。
LIMIT 10を追加すると、上位の10行が表示されます。
sqlite> SELECT UPPER(title), COUNT(title) FROM shows GROUP BY UPPER(title) ORDER BY COUNT(title) DESC LIMIT 10;
UPPER(title),COUNT(title)
"GAME OF THRONES",33
FRIENDS,26
"THE OFFICE",23
...
sqlite> SELECT UPPER(TRIM(title)), COUNT(title) FROM shows GROUP BY UPPER(TRIM(title)) ORDER BY COUNT(title) DESC LIMIT 10;
UPPER(title),COUNT(title)
"GAME OF THRONES",33
FRIENDS,26
"THE OFFICE",23
...
import csv
from cs50 import SQL
open("shows.db", "w").close()
db = SQL("sqlite:///shows.db")
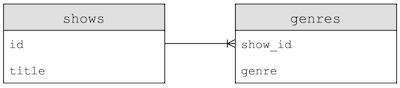
db.execute("CREATE TABLE shows (id INTEGER, title TEXT, PRIMARY KEY(id))")
db.execute("CREATE TABLE genres (show_id INTEGER, genre TEXT, FOREIGN KEY(show_id) REFERENCES shows(id))")
with open("Favorite TV Shows - Form Responses 1.csv", "r") as file:
reader = csv.DictReader(file)
for row in reader:
title = row["title"].strip().upper()
id = db.execute("INSERT INTO shows (title) VALUES(?)", title)
for genre in row["genres"].split(", "):
db.execute("INSERT INTO genres (show_id, genre) VALUES(?, ?)", id, genre)
sqlite> SELECT * FROM shows;
...
511 | MADAM SECRETARY
512 | GAME OF THRONES
513 | STILL GAME
sqlite> SELECT * FROM genres;
...
511 | Drama
512 | Action
512 | Adventure
512 | History
512 | Thriller
512 | War
513 | Comedy
id 512の番組 「GAME OF THRONES」 には、5つのジャンルが関連付けられています。
たとえば、すべてのミュージカルを検索するには、次のコマンドを実行します。
sqlite> SELECT show_id FROM genres WHERE genre = "Musical";
...
422
435
468
このクエリを入れ子にして、show_idのリストからタイトルを取得できます。
sqlite> SELECT title FROM shows WHERE id IN (SELECT show_id FROM genres WHERE genre = "Musical");
title
BREAKING BAD
...
THE LAWYER
MY BROTHER, MY BROTHER, AND ME
sqlite> SELECT DISTINCT(genre) FROM genres WHERE show_id IN (SELECT id FROM shows WHERE title = "THE OFFICE") ORDER BY genre;
genre
...
Comedy
Documentary
...
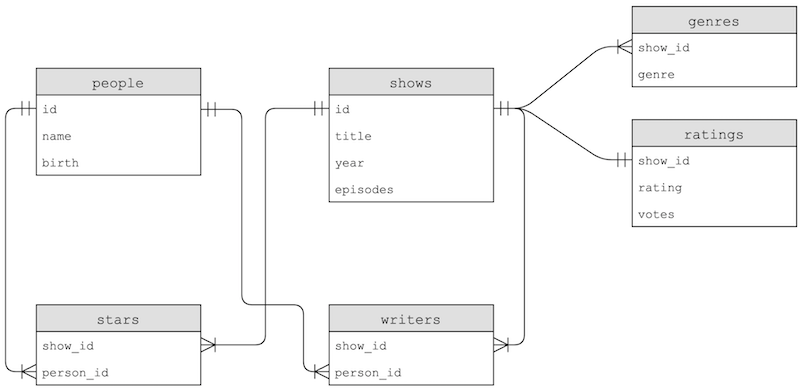
sqlite3> SELECT title FROM people
...> JOIN stars ON people.id = stars.person_id
...> JOIN shows ON stars.show_id = shows.id
...> WHERE name = "Steve Carell";
...
The Morning Show
LA Times: the Envelope
rows = db.execute("SELECT likes FROM posts WHERE id = ?", id);
likes = rows[0]["likes"]
db.execute("UPDATE posts SET likes = ? WHERE id = ?", likes + 1, id);